
 Este tutorial fué realizado para a BJA Biblioteca Jurídica Argentina, grupo dedicado a la digitalización de bibliografía Jurídica y de Ciencias Sociales. http://bibliojuridica.my-webs.org
Este tutorial fué realizado para a BJA Biblioteca Jurídica Argentina, grupo dedicado a la digitalización de bibliografía Jurídica y de Ciencias Sociales. http://bibliojuridica.my-webs.org
El futuro del libro es electrónico. Y ya llegó. La masiva digitalización, almacenamiento y distribución de libros en la red de redes es un hecho.
Existen muchos sitios de libros electrónicos entre los que recomiendo:
http://hansi.libroz.com.ar (Español)
Estos sitios son una referencia, existen miles de sitios, y todos los días aparecen nuevos.
El punto es ... como aparecen los libros digitalizados ?. La respuesta es muy simple, la mayoría son las ediciones digitales de los libros de papel distribuidas por las mismas editoras en formato electrónico, y por otra parte se encuentran los libros que son digitalizados "manualmente" por entusiastas de la digitalización.
La digitalización manual si bien no es compleja, tiene sus trucos.
Existen 2 tipos de digitalización manual, el OCR TEXTO y el OCR IMAGEN.
OCR TEXTO
Este es un método prehistórico, que se implementó cuando se comenzaron a aparecer los scanners de puerto paralelo y bajo Win98, cuando el ancho de banda también era una gran limitación. El método implica los siguientes pasos:
1) Escanear el libro completamente.
2) Realizar el OCR.
3) Corregir a mano el resultado del OCR.
4) Convertir el resultado en archivo DOC, RTF, TXT, LIT o PDF.
A FAVOR
1) Los libros ocupan pocos Kbs.
EN CONTRA
1) El OCR no es 100% confiable, como el resultado de la edición manual.
2) Demora muchísimo tiempo la corrección manual que implicar leer todo el libro para corregir errores.
3) No coincide la numeración de páginas entre el libro original y el libro digital.
Este método es el utilizado por casi todos los grupos de digitalización, del IRC o YAHOO.
OCR IMAGEN
Esta forma de digitalización, surge de un grupo dedicado a la digitalización de libros de derecho llamado Neopanopticum que luego se llamó El_panoptico y que hoy se llama BJA - Biblioteca Jurídica Argentina.
El problema para el grupo era que la corrección manual del OCR implicaba que se demoraba hasta 3 meses para tener listo un libro. Principalmente porque las notas al pié de página debían ser casi en todos los casos escritas desde cero. Esto es una norma para casi todos los libros científicos en los que las citas al pié son varias y extensas. Ademas los profesionales debemos citar las fuentes, lo que obliga a indicar además de la obra la página donde se encuentra el texto o referencia.
La digitalización de OCR TEXTO no mantiene excatamente la correlación de las páginas con las del libro original.
En razon de este problema se cambió completamente el sistema de digitalización, optándose por este proceso:
1) Escanear el libro completamente.
2) Recortar las imágenes de cada página eliminando margenes inútiles.
3) Realizar el OCR.
4) Convertir el resultado en PDF.
A FAVOR
1) Los libros son una copia exacta del original.
2) No existe ningún tipo de error.
3) Los PDF permiten buscar rápidamente una palabra dentro del libro.
EN CONTRA
No tiene ninguna contra, pero podría decirse que los libros en OCR IMAGEN ocupan un poco más que los de OCR TEXTO, pero eso hoy no es un inconveniente con el ancho de banda disponible.
OCR TEXTO PASO A PASO - Fuente:
http://www.katarsis-net.com.ar
Herramientas necesarias:
* Scanner
* Software OCR para reconocimiento de textos (esta guía está basada específicamente en el programa Abbyy Fine Reader versión 7 multilenguaje (en adelante FR) por su versatilidad para procesar y reconocer textos escaneados, aunque puedes utilizar cualquier otro -incluso el que ha venido seguramente con tu escáner- salvando las diferencias entre uno y otro)
* Procesador de textos Word 2000
1. Escaneando
El primer paso es acceder a la interfase del scanner desde dentro del FR para luego comenzar a escanear las páginas a 300 dpi en modo solo texto (evitando los modos de escala de grises, RGB color, y cualquier filtro de destramado) con un rango tonal tirando a claro para evitar sombras e imperfecciones. Los 300 dpi son para obtener un tamaño de letra considerable, de modo que sea fácil de reconocer para el OCR.
Lo más recomendable es escanear todo el libro de un tirón, digitalizando varias imágenes consecutivas (Ctrol+Shift+K). FR comenzará a escanear una imagen detrás de otra -sin preview- haciendo el proceso mucho más rápido que escaneando las páginas una por una manualmente. Pero antes de realizar ese paso, sería conveniente verificar algunas opciones del programa.
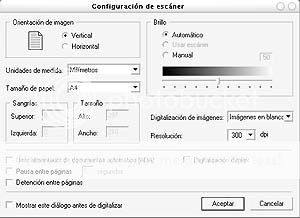
A medida que se escanean las diferentes páginas, es imprescindible verificar que la imagen salga con buen contraste entre las letras y el fondo, y con la menor cantidad de imperfecciones posible. Para corregirlos en caso que sea necesario, te puedes valer de la interfaz de escaneo que trae incorporada el FR en lugar de la de tu escáner. Para ello, accede a las Opciones del programa pulsando Ctrol+Shift+O y en la solapa de Digitalizar imagen marca la opción Usar Interfaz de FR, y luego pulsa el botón de Configuración del escáner para hacer los ajustes necesarios, sobre todo el de Brillo (nivel de umbral). Si tu escaner es muy rápido, puedes dejar marcada la opción de Pausa entre páginas y especificarle el tiempo que creas adecuado, de manera de tener el tiempo suficiente como para sacar el libro del escaner, pasar de página y volver a introducirlo entre escaneo y escaneo. En la solapa de Digitalizar
también asegúrate de marcar las casillas de Convertir imágenes en color o escala de grises a blanco y negro y Limpiar imagen. Haz las pruebas que creas convenientes hasta obtener un buen resultado de imagen y mantener el ritmo adecuado de escaneo.
Si el tamaño del libro lo permite, escanea de dos páginas a la vez en sentido horizontal a la cama del escáner. FR tiene la opción de escanear múltiples páginas, enumerando automáticamente las imágenes. Para lograr esto, accede a las Opciones del programa, y en la solapa Digitalizar imagen marca la casilla de Separar páginas dobles. Marca también la opción de Detectar orientación de imagen, asegurándote de poner la página de numeración inferior en el ángulo de inicio de escaneo (generalmente es la esquina superior izquierda de la cama del escáner), con el fin de que FR ordene la numeración de las imágenes adecuadamente.
Nota: si el FR encuentra dificultades para reconocer la orientación de las páginas o tu máquina se vuelve muy lenta con esta opción activada, se recomienda hacer lo siguiente luego de escanearlas a todas: utiliza la herramienta de Lote (proceso múltiple de imágenes) para darles un sentido horizontal a todas las imágenes automáticamente. Luego creas otro Lote con la opción de Separar páginas dobles para que FR separe todas las imágenes en páginas individuales con un solo click.
2. Controlando la paginación
A medida que se van escaneando las páginas, el FR va mostrando miniaturas (thumbnails) de las páginas escaneadas en la ventana izquierda, asignándole un número que le ha correspondido al pie de la misma. Al finalizar el escaneo, asegúrate de hacer coincidir el número de la primera página con el número de esa página en el libro; luego puedes hacer que el programa reenumere las demás páginas. Por último, verifica que cada página se corresponda con el número de la miniatura correspondiente.
Es indispensable controlar de que no te hayas salteado ninguna página (o que alguna la hayas escaneado, por distracción, dos veces), como así también su correcto orden.
3. Definiendo los bloques del texto a reconocer
Antes de indicarle al programa que reconozca el texto, hay que definir en cada página las áreas o bloques de texto que se deseen reconocer (en caso contrario, el programa no las procesará). Esto puede hacerse manualmente página por página (menú Procesar > Analizar distribución; Ctrol+E), o automáticamente y para todas las páginas (Ctrol+Shift+E).
En el caso del análisis automático, una vez que FR ha definido las áreas de reconocimiento se recomienda:
* eliminar del mismo los números de página, los cabezales y pies de página.
* corregir aquellos errores que FR hubiera interpretado como dibujos o textos.
* corregir los bloques de texto que FR hubiera podido saltearse.
* verificar el orden de los bloques de texto a reconocer.
Para ello, puedes valerte de la barra de herramientas lateral en la ventana de Imagen para agregar/corregir/eliminar bloques de texto e imagen.
4. Reconociendo el texto
Para esta altura ya se le puede dar la orden al programa de reconocer (leer) todas las imágenes (Ctrol+Shift+R). Opcionalmente, se pueden reconocer páginas individuales (Ctrol+R) o un bloque de texto en particular (Ctrol+Shift+B).
El proceso de cómo funciona es el siguiente: FR reconoce letra a letra según su contorno y cuando se encuentra con un espacio en blanco, determina el final de una palabra. Esa palabra luego es chequeada contra su diccionario; si encuentra un error la reemplaza por la que figura en el diccionario y señala el cambio con un marcador celeste; si la palabra no figura en su diccionario la escribe según el reconocimiento y la señala con el marcador.
Una vez que FR terminó de reconocer todo el texto, es necesario recorrer página por página revisando las marcas celestes. Puede que una palabra marcada con este color esté bien escrita, en ese caso no es necesario hacer nada. Caso contrario, puedes verificar el error viendo la ampliación de imagen que aparece en la ventana superior y corregirlo. Esta etapa es muy importante ya que el FR puede detectar errores que el Word no puede reconocer.
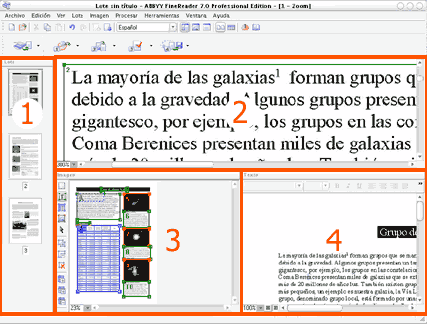
Vista general del Fine Reader: 1. Ventana de miniaturas (thumbnails); 2. Ventana de ampliación de imagen; 3. Imagen completa y definición de bloques de texto e imágenes dentro del documento 4. Texto reconocido
Para realizar la tarea de corrección, conviene ampliar la ventana de la imagen ampliada y el texto reconocido y trabajar con ellas. Para modificar el factor de ampliación, haz click derecho sobre esta ventana y luego seteas la escala.
5. Guardando el texto reconocido
FR tiene varias opciones para guardar el texto. Lo más conveniente es guardarlo en .rtf, o documento de word.
6. Afinando el texto en Word
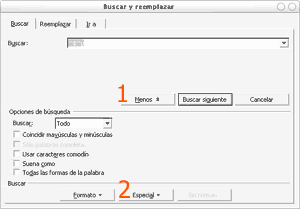
Diálogo de Búsqueda avanzada en Word: 1. Botón para acceder a las opciones avanzadas de búsqueda; 2. Pulsando el botón Especial, podrás introducir entidades especiales para su búsqueda.
Para la corrección de ciertos errores puedes utilizar la herramienta de búsqueda de Word (Menú Editar > Buscar), con el fin de detectarlos automáticamente. En la ventana de diálogo de búsqueda, asegúrate de que se muestren las opciones avanzadas pulsando el botón Más. En Especial, encontrarás una serie de opciones que usarás para corregir algunos errores comunes de reconocimiento de texto.
Párrafos interrumpidos
Debido a que el libro tiene dimensiones diferentes a la de un documento en pantalla y usa diferentes tipografías y tamaños, el texto reconocido y cargado en Word se presentará con párrafos interrumpidos. Para detectarlos rápidamente puedes realizar una búsqueda avanzada. Presiona Ctrol+B para abrir el cuadro de Búsqueda, habilita las opciones avanzadas y pulsando Especial seleccionas el item de [cualquier letra[/img] y luego el de [marca de párrafo[/img]. En la línea del buscador, aparecerá lo siguiente:
^$^p
Luego de eso, inicias la búsqueda.
(explicación: ^p indica el salto de párrafo; ^$ cualquier letra. Una vez ubicado el caso a corregir hay que detenerse y corregirlo manualmente.)
También deben buscarse las líneas truncas luego de una coma, punto y coma, y dos puntos, ingresando:
,^p
;^p
:^p
respectivamente.
Saltos de página con corte de palabra.
Los saltos de página con corte de palabra se pueden corregir automáticamente buscando la secuencia guión + marca de salto de párrafo (-^p) y reemplazándola por nada. Esto suprimirá todos los guiones y los salto de párrafo dejando las palabras nuevamente unidas.
Diferenciar y jerarquizar los títulos y subtítulos para diferenciarlos del resto del texto
La única manera de chequear esto es recorrer el texto entero. Lo más conveniente es asignarle un estilo a los títulos y otro a los subtítulos, definiendo un estilo diferente (por tipografía y tamaño) al del texto general y al de cualquier otro estilo usado.
Corrección de errores que a veces no son detectados por el corrector automático
En el OCR hay errores comunes que suelen aparecer frecuentemente. Estos son:
* Confusión del nexo coordinante y por v : la solución es Buscar y reemplazar todos los (espacio)v(espacio) por (espacio)y(espacio), ya que en la sintaxis castellana, la v corta no va suelta en ningún caso.
* Reemplazo de letras por dígitos, y comprobación de dígitos en el documento: la solución es realizar una búsqueda avanzada seleccionando [cualquier número[/img]. Conviene hacer esta comprobación porque sucede a menudo que el texto original tiene defectos que hacen que el OCR confunda por ejemplo él con 61′ o la letra l con 1 , etc.
7. Uso del corrector ortográfico en Word
Dirígete al menú Herramientas > Opciones, y en la solapa de Ortografía y gramática, setea la opción de Estilo de escritura a Verificación exhaustiva. Luego inicia la corrección interactiva en Word de todo el documento pulsando F7′. También asegúrate, habiendo previamente seleccionado todo el texto (Ctrol + E), de definir el idioma a español desde el menú Herramientas > Idioma.
Un problema frecuente es que Word muestre los nombres propios como errores, ya que por lo general no se encuentran en su diccionario. Para evitar esto, al llegar a un nombre propio, indicale la opción de Omitir todos de manera que no vuelva a preguntar por lo mismo. Aplícalo también con palabras raras o propias del texto.
8. Corrección por lectura
Aún en la actualidad, los programas no tienen la inteligencia suficiente como para comprender un texto; simplemente se rigen por sus diccionarios. Puede que exista un error pero al detectar que una determinada combinación de letras corresponde a una palabra que figura en su diccionario, sencillamente la interpretará como correcta.
Si el error está en el original impreso en papel (porque sucede que aún en estos casos haya errores de tipeado, párrafos cortados y hasta incluso omisión de páginas), entonces la máquina no podrá ayudarnos. En este sentido es importante hacer una corrección a conciencia, a pesar de que ello implique tiempo y dedicación extra. Por eso es conveniente trabajar con libros ya leídos y que sepamos que no tengan grandes errores en su impresión, por lo que tranquilamente se podrá saltear este paso.
Notas finales
Una vez que tienes listo el texto, guardalo preferentemente en formato .rtf. La ventaja de este tipo de archivos es que conservan el formato del documento original, pudiéndose abrir en prácticamente cualquier procesador de textos, independientemente de su versión e incluso en múltiples plataformas (PC/Mac). También puedes convertirlo a formato .pdf para su publicación, si es que tienes las herramientas necesarias y estás seguro de que el texto no contiene errores, ya que una vez publicado, este formato no admite modificaciones.
Un último consejo: lo mejor es organizarse con otras personas que tengan fines comunes y que cada una se ocupe de una tarea específica. Es decir, que alguien se puede ocupar del escaneo y OCR, mientras que al finalizar algun otro puede hacerse cargo de la etapa de corrección, otro del trabajo en Word, revisión, etc.
OCR IMAGEN PASO A PASO
Para digitalizar un libro hacen falta el software Abby Fine reader 7 y paciencia.
Nosotros establecimos un estandart a 300 dpi en blanco y negro. Con eso escaneamos todo el libros salvo las tapas que las escaneamos a color.
Lo primero que haremos es crear un nuevo batch (lote en castellano), para que todo tu trabajo quede en una sola carpeta y no se te vayas a confundir con otras imágenes que puedas tener.

Guarda el batch, esto es muy importante para que no vayas a perder ningún archivo en el proceso.
Si por alguna razón debes parar tu trabajo y seguir más tarde u otro día, después sólo será cosa de que abras este batch con el FR y recomenzar donde quedaste.


Ahora viene el momento de comenzar el scan. Lo primero que tienes que hacer es señalarle algunos parámetros a FR para que salga bien tu trabajo y sea más fácil.

Selecciona Split dual pages, asi el programa dividirá automáticamente las páginas de los libros cuando estos los escanees de a dos páginas a la vez. Ojo: si el libro es muy grande y sólo puedes escanear página a página no es necesario que selecciones esta opción.
También selecciona Detect orientation (durant recognition), para que el FR enderece aquellas páginas que han quedado en una posición distinta a la del libro al hacer el scan.

Guarda las opciones y comienza el scan.
En este caso, la mejor opción de trabajo es seleccionar en el ícono que te aparece arriba scan multiple images, asi el programa comenzará automáticamente a escanear todas las páginas que sea necesario, y sólo se cerrará una vez que tú manualmente se lo indiques cuando ya esté todo el libro en formato de imágenes.

Las opciones de scan van a variar de acuerdo a las especificaciones de tu scanner. Aquí nosotros recomendamos usar el controlador propio de cada aparato. Si no sabes usarlo recurre a los manuales que deben haber venido con tu scanner.
El scan debe realizarse: en blanco y negro, resolución de 300 dpi, cuidando de que las imágenes no salgan ni muy claras (porque se pueden perder contenidos) ni muy oscuro (porque pueden aparecer muchas manchas)
VEAMOS COMO TRABAJAR CON EL LIBRO SOBRE EL SCANNER
Primero ver si el libro se puede escanear a página doble sin que sobresalgan márgenes.
El libro debe encuadrarse prefectamente dentro del campo del scanner:

Veamos el margen Izquierdo:

Veamos el margen Derecho:

Veamos ahora como se debe trabajar con el lomo del libro.
MUY MAL: queda muy abierto y genera una franja negra que puede superponer texto entre las dos páginas.

PERFECTO: No se deja espacio abierto y la digitalización es perfecta.

El libro siempre debe encuadrarse entre el angulo recto izquierdo del scanner. Tomándose la linea vertical izquierda y la base horizontal como referencias para encuadrar correctamente el libro en el scanner.

El lomo del libro tiene que estar siempre lo más bajos posible, para evitar la franja negra que se produce por dejar espacio.

Los libros a escanearse a página simple. Son aquellos libros que no pueden escanearse a página doble por el formato propio del libro, ya que supera el formato A4, esto implica escanear hoja a hoja. Este proceso importa dubplicar el tiempo de escaneo, veamos la secuencia:
Primero escaneamos una página:

hora rotamos el libro en el sentido de las agujas del reloj 360º y escaneamos la otra página:

Lo mejor es siempre sacarle la tapa al escanner o desarmarlo para trabajar con mayor comodidad.
Una vez tengan todo el libro escaneado, guarden el lote por seguridad.
CONSIDERACIONES PREVIAS A DIGITALIZAR
1) El tamaño del libro.
Resulta muy importante tener presente el tamaño de la encuadernación del libro a digitalizar, antes de iniciar el trabajo de digitalización se debe presentar el libro sobre el scanner para calcular si el mismo resulta apto para una rápida digitalización.
La mayoría de los escanners tienen una superficie de escaneo equivalente al tamaño de hoja A4. Eso significa que presentando una hoja A4 sobre la superficie del libro abierto y vemos que superficie cubre el A4 sobre las dos hojas de libro.
Lo ideal resultaría que el libro abierto a doble página encaje perfectamente dentro del campo del scanner y de la hoja A4, sin que sobresalgan márgenes laterales, inferiores o superiores.
Lo ideal siempre resulta que se puedan escanear a pagina doble, pero en muchos casos no resulta posible ya que el tamaño de las hojas del libro no lo permite, y el escaneo debe realizarse página a página.
El standart para escanear libros a página doble es sobre un libro de 23 x 16 cm. si las dimensiones son mayores el libro debe escanearse página a página.
2) Que libro elegir para escanear primero ?
Digitalizar un libro como todas las cosas implica un proceso de apredizaje, lo que nos lleva a sugerir que sus primeros libros digitales deben ser de pocas páginas, entre 100 y 300. Esto tiene su razón para familiarizarse con el escaner que utiliza y el tiempo que este demora entre pasada y pasada, y practicar constantemente la forma de encuadrar perfectamente el libro dentro de la superficie de escanner en el breve lapso de segundos que le toma al escanner hacer otra pasada para escanear.
Sus primeras digitalizaciones tendran errores, hojas que no se ven bien por eso hay que practicar y practicar hasta que Ud. pueda escanear un libro y al mismo tiempo leer otro en la pantalla, navegar por internet o ver un DVD, una vez que se familiarice con los libros y con su escanner, verá que no hay límites para digitalizar, solamente el tiempo que desee invertir en ello.
3) Que es mejor un libro nuevo o uno viejo ?
Lo mejor siempre es bibliografía actualizada, y de consulta constante. Hay textos clásicos indispensables y libros nuevos que casualmente no dicen nada nuevo. Cada profesional o estudiante conoce los autores de cita y las obras de referencia en su campo.
Los libros nuevos suelen implicar un trabajo extra ya que para abrirlos bien a doble página sobre la superficie del escanner se debe aplicar un esfuerzo superior ya que su encuadernación se encuentra virgen, sin aperturas, en cambio los libros ya usados y abiertos son muy fáciles de exponer sobre el escanner.
Existen editoriales con determinado tipo de encuadernación
que puede facilitar o complicar en más o en menos la digitalización de un libro.
4) Porqué se deben evitar los libros subrayados ?
Los libros con texto subrayado dificulta el reconocimiento de texto, y visualmente resulta molesto para leer. Si la obra vale
la pena se debe recurrir a la goma de borrar y borrar los subrayados.
Si el subrayado fué realizado con tinta, y el mismo permite la lectura y las hojas subrayadas no superan el 10% del total de
hojas de la misma, se acepta, hasta que se consiga un obra sin subrayar o en mejor estado.
5) Cuanto tiempo toma escanear un libro ?
Eso depende exclusivamente de la velocidad de su escaner y de la práctica. Su escanner puede ser muy rápido para sus manos y
solo con la práctica se adquiere la velocidad para pasar las hojas y acomodar el libro sobre el escanner en forma correcta,
la clave está en la práctica.
Pero para hacer un cálculo promedio un escanner demora entre cada pasada entre 12 y 20 segundos, demora el mismo tiempo ya
sea una página simple o doble, ya que la pasada la realiza sobre toda la superficie expuesta del escanner.
Existe una gra diferencia de velocidad entre los escanners que se conectan en puerto paralelo y los USB, la recomendación es
que se tenga instalado por sistema operativo Windows XP y un escanner USB con eso la velocidad aumenta considerablemente,
utilizar Windows 98 o un escanner por puerto paralelo ralentiza todo el proceso.
Una buena opción es comprar un escanner HP 1410 que es muy rápida y económica alrededor de los $ 200, una multifunción que como impresora es un excelente escanner. No sirve como impresora pues consume mucha tinta (que encima es costosa) pero el escanner no necesita de tinta ;)
Tenemos entonces para empezar digamos en el peor de los casos 20 segundos por cada 2 páginas, eso hace 6 páginas por minuto, 60 páginas cada 10 minutos, y 360 por hora.
POR 12 SEGUNDOS:
002 páginas - 001 pasada ( 1 x 12) = 0012 segundos
010 páginas - 005 pasadas ( 5 x 12) = 0060 Segundos
050 páginas - 025 pasadas (25 x 12) = 0300 segundos
100 páginas - 050 pasadas (50 x 12) = 0600 segundos
En una hora se digitalizan (3600/12) x 2 = 600 páginas
POR 16 SEGUNDOS:
002 páginas - 001 pasada ( 1 x 16) = 0016 segundos
010 páginas - 005 pasadas ( 5 x 16) = 0080 segundos
050 páginas - 025 pasadas (25 x 16) = 0400 segundos
100 páginas - 050 pasadas (50 x 16) = 0800 segundos
En una hora se digitalizan (3600/16) x 2 = 450 páginas
POR 20 SEGUNDOS:
002 páginas - 001 pasada ( 1 x 20) = 0020 segundos
010 páginas - 005 pasadas ( 5 x 20) = 0100 segundos
050 páginas - 025 pasadas (25 x 20) = 0500 segundos
100 páginas - 050 pasadas (50 x 20) = 1000 segundos
En una hora se digitalizan (3600/20) x 2 = 360 páginas
Esta tabla muestra claramente el tiempo que toma la digitalización de páginas y asimismo sirve de guía para calcular el tiempo "optimo" que puede tomar digitalizar un libro conforme la cantidad de páginas que tenga. Que en el peor de los casos se calcula que en una hora se pueden digitalizar 360 páginas.
9) Se debe escanear todo el libro ?.
Si. Los libros se escanean desde su tapa a color hasta la última página, no importa que tenga páginas en blanco al principio o al final, la digitalización implica copias digitalies exactas del libro. Las copias deben ser exactas por el hecho que los libros son utilizados para realizar citas textuales, indicando en número de página, que de otra manera perderían su valor.
14) Cuales son las ventajas de la digitalización ?
VELOCIDAD DE ACCESO Y CONSULTA: Acceso inmediato a la obra o articulo necesario, y consultar tantos libros digitales al mismo tiempo como se necesite en la misma pantalla.
COSTO CERO: La digitalización no implica un costo, salvo de tiempo no de dinero.
AHORRO DE ESPACIO: Los libros digitales no ocupan espacio ni en el escritorio ni en la biblioteca.
PRESERVACIÓN: Los libros digitales no se deterioran por el paso del tiempo, no se ponen amarillos con los años, no son
alergicos al agua, o la humedad y son inmunes a las ratas. Los libros digitales no necesitan mantenimiento ni reencuadernación.
EL Papel sufre un proceso natural de oxidación por su exposición al aire, lo que lo deteriora notablemente con el paso del tiempo.
Que está esperando para digitalizar su primer libro ?
Mis primeros libros digitalizados con el método OCR IMAGEN 
 DESCARGAR - Felipe Pigna - Mitos de la Historia Argentina Tomos 1 y 2 ESCANEAR COMICS / Editando con Photoshop
DESCARGAR - Felipe Pigna - Mitos de la Historia Argentina Tomos 1 y 2 ESCANEAR COMICS / Editando con Photoshop Fuente:
http://lamansion-crg.net
01. captura
Éste es realmente el paso más importante de todos. Para una página de tamaño normal de comic, escanea la imagen a 300 dpi. Aunque la imagen luego se vaya a reducir el resultado es notablemente mejor de esta manera. Para cambiar el tamaño de una imagen es necesario ir al menú: image > image size. En resolution asegurarse de que el valor está en pixels/inch y cambiar donde pone 300 por 150. Al hacerlo es importante también comprobar que esté activado resample image:bicubic, para que cambie el tamaño en pixels y no sólo en valores de impresión.
Imagen escaneada a 150 dpi

Imagen escaneada a 300 dpi y reducida a 150 dpi

En el Canal Azul RGB se pueden apreciar mejor las diferencias


Mucha gente escoge el tamaño del ancho del comic en base a la resolución de su monitor para que coincidan, de manera que si tienen una resolución de 1024x768 el tamaño del ancho de la página del comic lo hacen de 1024. Esto es un error, ya que la resolución del monitor es variable, y aunque 1024 es actualmente el ancho más extendido, es mas que probable que no lo sea en el futuro, de la misma manera que antes la resolución más extendida era 800x600 (y sucesivamente...). De manera que lo ideal es escoger un tamaño en el cual el comic se lea suficientemente bien sin perder detalles, sin un pixelado exagerado y sin que resulte un tamaño de archivo final enorme. En general para un tamaño de página normal entre 150 y 160 dpi suele ser suficiente.
Es importante escanear con unos valores de brillo y contraste neutros, si el comic resulta claro u oscuro ya se utilizarán más tarde herramientas para corregirlo, las herramientas de corrección de brillo y contraste automáticas suelen dejar el comic demasiado contrastado y con detalles empastados. Otra razón de utilizar valores neutros es para que a la hora de corregir o mejorar la imagen se utilicen los mismos valores para todo un comic en vez de hacerlo página por página, pero principalmente los niveles automáticos o Autolevels quedan fatal especialmente en escaneos de papel normal. Una vez reducido el tamaño se le puede aplicar un filtro que da muy buen resultado: el filtro unsharp Mask (Máscara de enfoque). Aplicado con los valores: cantidad: 50% y radio:1px
02.Giro y recorte
El siguiente paso es girar la página. Normalmente es difícil escanear la página de manera que esté completamente recta y realmente cuesta menos girarla en photoshop que procurar el escaneo perfecto. Para girar la página podemos seleccionar un área o toda la página (ctrl+a) y luego girar la selección (ctrl+t) "a ojo". Un método más preciso es utilizar la herramienta Measure Tool (i). Seleccionamos la herramienta y pinchamos en una esquina del comic, mantenemos y arrastramos hasta otra esquina para indicar al programa la inclinación que debe corregir: Al escoger la opción de menú: Image> rotate canvas > arbitrary... el valor que sale es exactamente el que necesitas para girar la página.



También podemos utilizar la opción de menú rotate canvas sin aplicar el measure tool "a ojo" . Cuando llevamos unas cuantas decenas de comics es normal acertar con el ángulo aproximado. Lo siguiente será recortar la imagen, para lo que utilizaremos la herramienta crop tool (c) y ya podemos guardar la página. Con la herramienta seleccionamos el área y recortamos haciendo doble clic en el interior de área seleccionada. Podemos tirar de los bordes para aumentar o disminuir el área seleccionada. Con la herramienta Crop Tool podemos además girar y recortar la imagen en un paso. Si acercamos el ratón a las esquinas nos aparecerán unos tiradores con los que podremos girar la imagen, luego hacemos doble clic y la tenemos recortada y girada con un solo paso.
03. Corrección tonal.
Photoshop ofrece una gran cantidad de herramientas destinadas al tratamiento de la imagen, conociéndolas en profundidad y combinando unas y otras pueden dar unos resultados espectaculares, sumándolo a la capacidad de crear srcipts (acciones), que automatizan estas tareas hacen que el esfuerzo para conseguirlo sea mínimo, unas pruebas en una página (o dos) creas una acción y la aplicas a todo un comic que previamente has escaneado. Muchas de las técnicas son algo complejas y requieren muchos pasos, intentaré ir de menos a más.
He leído en tutoriales recomendar utilizar el automático de Photoshop. Image > adjustments > Autolevels (ctrl+shift+l). En mi opinión es un error utilizar autolevels. No hay dos comics iguales y no se puede generalizar, pero normalmente usar autolevels tiene como consecuencia un resultado demasiado oscuro. En la mayoría de los comics el color negro no llega al negro "puro", por lo que forzarlo supone un aumento del contraste, ruido etc. Un valioso consejo en este sentido es que siempre es mejor "no llegar" que "pasarse". Por no mencionar que alguna página que esté planteada como especialmente clara u oscura aparecerá con las tonalidades desvirtuadas. .

Antes de comprobar los niveles es muy importante asegurarse de que nuestro monitor está correctamente configurado. Una manera simple de saberlo es utilizando un par de imágenes de corrección de gamma. En la primera imagen tenemos que ver el cuadrado del centro de una tonalidad lo más parecida posible al recuadro de fuera, en la segunda imagen debemos poder distinguir (aunque sea levemente) los cuadrados negros de los grises oscuros.
Éstas imágenes y el programa de configuración lo encontramos en el panel de control > adobe gamma siempre y cuando tengamos instalado Photoshop.
Filtros de "mejora"
Es importante dedicar unas palabras a los filtros desentramar (noise>despeckle) y desenfocar (Blur) en todas sus modalidades. Ya que las páginas editadas tienen una trama, es lógico acudir al filtro desentramar para que arregle ese pequeño problema, sin embargo después de muchas pruebas y contrastar opiniones está muy claro el asunto, como dicen en algunos foros guiris "Blur is evil". Puede que en algunas ocasiones muy puntuales alguna de estas herramientas, especialmente smart blur puedan ser de ayuda, pero se deben utilizar con cuidado y a la menor duda desecharlos, además de que consumen mucho procesador. También es importante recalcar que no es muy buena idea aplicar el filtro para aumentar la saturación, los filtros de niveles ya lo hacen de alguna manera, y es una manera fácil de perjudicar la página a la hora de guardar jpg, cuanto más saturado esté, mas información necesitará.
Niveles
Es aquí donde el programa echa el resto en capacidad de mejora de una imagen. Hay una regla principal: NADA DE AUTOLEVELS. El cuadro de diálogo niveles image > adjustments > levels (Ctrl+L) permite corregir la gama tonal y el equilibrio de color de una imagen ajustando la intensidad de las sombras, los medios tonos y las luces de una imagen, permite modificar la imagen en general (RGB), o cada canal de color por separado (Rojo, Verde, Azul). El histograma sirve como guía visual para ajustar la tonalidad.

En un comic de papel normal, la imagen aunque sea buena se puede mejorar aplicándole unos ajustes de niveles en un solo paso. Vamos a ver como trabajan los niveles sobre un ejemplo:
Imagen Original

Modificada



En el canal RGB llevamos la flecha de la izquierda hacia la derecha (1) esto acerca los tonos oscuros al negro, no lo llega a alcanzar para no forzar los tonos. La flecha de en medio (2) la llevo ligeramente a la izquierda, esto aclara los tonos medios, que se han oscurecido en el paso (1). La flecha de la derecha (3) la llevo ligeramente a la izquierda, esto quita textura del papel, pero debe hacerse con cuidado, puedes quitar detalles del dibujo. Por último en el canal Azul llevo la flecha de la derecha (4) hacia la izquierda para quitar un ligero tono amarillento típico de ese papel.
Vamos a ver un ejemplo de un comic antiguo amarilleado por el tiempo. El proceso sería el mismo, sólo que habría que tratar un poco más el canal azul
Original

Modificando el canal azul y RGB

Modificado con autolevels



Vemos que el autolevels no ha eliminado por completo el tono amarillo y ha dejado la imagen oscura.
04.Acciones
Una acción es una serie de comandos que puedes reproducir en un fichero o en varios. La mayoría de comandos y herramientas se pueden grabar en acciones. De lo que se trata es de una vez capturada la página podamos automatizar todas las tareas para que el trabajo de escaneo requiera el menor esfuerzo consiguiendo los mejores resultados. Lo primero de todo es planificar bien el trabajo con antelación: escanear una página de ejemplo para comprobar la resolución y si la imagen necesita mejorar la tonalidad, Los comic impresos en buenos papeles no suelen necesitar mucha corrección tonal. Un consejo para probar valores de corrección: puedes duplicar la capa (En la pestaña Layers pinchas en la capa y arrastras al botón create new layer.) aplicar valores y así comprobar fácilmente las diferencias haciendo clic en el ojo de la capa. Como método personalmente prefiero escanear, corregir inclinación, bajar resolución, aplicar mascara de enfoque y guardar imágenes en formato TIFF, con las imágenes guardadas escojo los valores de corrección de niveles y curvas y aplico una acción a todo el directorio que corrige niveles y guarda JPG calidad 7-8 dependiendo del comic. Este método permite comprobar todo el trabajo de una vez y corregirlo fácilmente sin tener que escanear de nuevo.
Acción de ejemplo
Para crear una acción capturamos una imagen, nos vamos a window>actions (F9) para que nos aparezca la pestaña de acciones le damos a la flechita (1) y a new set para crear una carpeta con las acciones que vamos a utilizar con el nombre comic.



Le damos al botón create new action (2) y automáticamente se queda activado el botón de grabar, lo que hagamos a continuación formará parte de la acción. Una vez rotada la imagen, le bajamos la resolución, la recortamos con la herramienta crop, le aplicamos el filtro unsharp mask y la grabamos como Tiff. le damos al botón stop de la pestaña de acciones, para parar la grabación, y a continuación señalamos aquellos pasos de la acción (3) cuyos valores cambian con cada imagen, es decir: rotar, recortar y guardar, cuando la acción se reproduzca en una imagen, nos preguntará los valores, en el caso de crop nos aparecerá el tamaño de marco de la acción grabada, esto está muy bien, porque así todas las paginas de un comic tendrán el mismo tamaño, si queremos, para guardar, nos preguntará el nombre del fichero. Si el comic no necesita corrección tonal, podemos guardar en jpg tal cual en este paso y no continuar, pero si al comic le viene bien un lavado de cara guardamos en tiff todo el comic, abrimos una página de ejemplo y le aplicamos las herramientas de corrección tonal grabándolas en una acción. Una vez hayamos creado todo un set de acciones y tengamos previamente guardado en una carpeta el comic en cuestión, nos vamos a File>automate>batch donde le decimos la acción que debe ejecutar en la carpeta seleccionada, la acción aplicará los ajustes en todo el directorio de imágenes grabándolas en el formato que hayamos escogido previamente en la acción.
05.Formatos de grabación
Entendiendo que vamos a grabar las imágenes para que se puedan ver con el Comic Display Reader hay tres formatos en los que se puede grabar una imagen: JPG, GIF y PNG. Para imágenes en color el JPG es el adecuado. El formato PNG y GIF son adecuados para imágenes en blanco y negro. Para escanear comics en blanco y negro es recomendable escanear en escala de grises, 256 bit de grises, nunca imagen en B/N de 1 bit de color. Corregimos niveles de la misma manera que lo hacemos como una imagen en color, procurando no contrastar mucho la imagen para que los bordes no se queden pixelados y para grabar podemos hacerlo de dos maneras: En Photoshop File > Save for Web escogemos el formato PNG-8 y guardamos la imagen. Para guardar en GIF convertimos la imagen de escala de grises a RBG y luego a indexado: image > mode > indexed color con los valores: palette: local (adaptive) colors: 16 forced: black and white, con tansparency desactivado y dither: diffusion, y guardamos en GIF, apenas hay diferencia de tamaño entre GIF y PNG, lo importante es no guardar una imagen sin color en JPG, porque ocupará mucho más que en los otros dos formatos y no se verá mejor. Las imágenes que no contienen color, pero tienen muchas tonalidades distintas de grises es preferible grabarlas como JPG, ya que en esos casos el tamaño del fichero GIF y PNG puede superar al JPG. Photoshop ofrece tres maneras de grabar el JPG: baseline (standard) baseline optimized y progressive. El progressive tiene un entrelazado que permite previsualizar la imagen antes de que termine de cargar, debe evitarse grabar en progressive por dos motivos: a) Hace el fichero de mayor tamaño de lo que debería ser. cool.gif Es molesto ver la previsualización cuando te desplazas o cargas la imagen y tarda más.
06.Otros procedimientos.
Hay una serie de problemas comunes a los que nos enfrentamos los escaneadores, intentaré aportar unas soluciones que te ofrece la aplicación. A partir de ellas podremos afrontar nuevos problemas mucho mejor.
Páginas dobles
Para solucionar el problema de páginas dobles existen muchas soluciones y la más adecuada depende de las características de la imagen en particular. La más precisa probablemente sería utilizar una aplicación de terceros de panoramas, pero para no liarnos con otras aplicaciones vamos a centrarnos en dos soluciones simples. Tenemos dos situaciones típicas: a) Es un comic cuyos bordes están perfectamente escaneados y el borde de la página coincide perfectamente con la otra. b) El borde no está bien escaneado por tratarse de un volumen grande o los bordes no coinciden bien.
Para la situación "a" pongamos que tienes las dos imágenes abiertas, seleccionas una (Ctrl+a) y la copias (Ctrl+c) vas a la otra imagen, maximizas la ventana, con la herramienta lupa (z) haces un zoom hacia atrás hasta que veas la imagen completa en pequeñito (alt+click) y escoges la herramienta crop (c). Pinchas en uno de los tiradores hasta agrandar la imagen a más del doble hacia el lado en el que quieres poner la segunda página. Pegas la página que tenías en el portapapeles (Ctrl+v) y con la herramienta move tool (v) vas ajustando. Con las flechas de dirección puedes mover pixel a pixel hasta que ajuste. Para la situación "b" una solución elegante es al ajustar dejar un espacio en blanco en medio para suavizar las diferencias.
Bordes de página
Cuando escaneamos volúmenes es muy común encontrar bordes oscurecidos porque se crea una distancia entre escáner y página. Existe un procedimiento que corrige este error de manera eficaz, especialmente en una imagen en B/N, en una imagen de color es un poco más complejo y con resultados mas dudosos, ya que además de tonalidad la imagen pierde también color en los bordes. Voy a explicar el procedimiento sólo para una página en B/N :

En primer lugar visualizamos la regla (Ctrl+R) pinchamos en uno de sus bordes verticales y arrastramos una guía hasta un poco más allá de donde acaba el gris no deseado. A continuación visualizamos la pestaña de canales window > channels y creamos un canal nuevo dándole al botón create new channel. Nos aseguramos de que el color frontal es blanco y el color de fondo negro, en la barra de herramientas seleccionamos la herramienta gradient tool (G) y creamos un degradado desde el borde izquierdo hasta la línea guía. Hacemos click en el canal RGB o Gray y seleccionamos el canal que acabamos de crear haciendo (Ctrl+click) en el canal o mediante el menú selection>load selection.

Una vez que tenemos cargada la selección aplicamos niveles (Ctrl+L) arrastrando la flecha de la derecha hacia la izquierda hasta eliminar por completo el gris de fondo controlando también los tonos de la imagen para tratar de ajustar lo mejor posible el resultado.













